
El jueves, la plataforma de alojamiento de IA Hugging Face superado 1 millón de listados de modelos de IA por primera vez, lo que marca un hito en el campo del aprendizaje automático en rápida expansión. Un modelo de IA es un programa informático (que a menudo utiliza una red neuronal) entrenado con datos para realizar tareas específicas o hacer predicciones. La plataforma, que comenzó como una aplicación de chatbot en 2016 antes de convertirse en un centro de código abierto para modelos de IA en 2020, ahora alberga una amplia gama de herramientas para desarrolladores e investigadores.
El campo del aprendizaje automático representa un mundo mucho más grande que los grandes modelos de lenguaje (LLM) como los que impulsan ChatGPT. En una publicación en X, el director ejecutivo de Hugging Face, Clément Delangue escribió sobre cómo su empresa alberga muchos modelos de IA de alto perfil, como “Llama, Gemma, Phi, Flux, Mistral, Starcoder, Qwen, Stable diffusion, Grok, Whisper, Olmo, Command, Zephyr, OpenELM, Jamba, Yi”, pero también “999.984 más”.
La razón, dice Delangue, se debe a la personalización. “Al contrario de la falacia de ‘un modelo para gobernarlos a todos'”, escribió, “los modelos más pequeños, especializados, optimizados y personalizados para su caso de uso, su dominio, su idioma, su hardware y, en general, sus limitaciones, son mejores. De hecho, , algo de lo que pocas personas se dan cuenta es que hay casi tantos modelos en Hugging Face que son privados solo para una organización: para que las empresas construyan IA de forma privada, específicamente para sus casos de uso”.
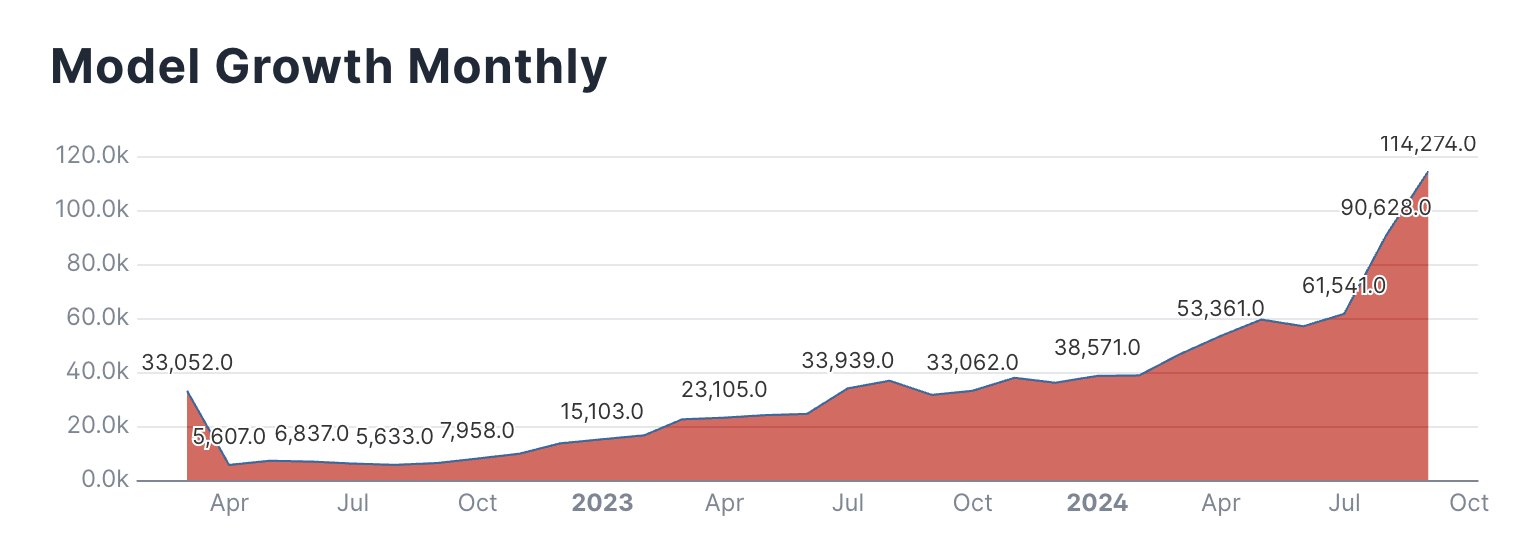
La transformación de Hugging Face en una importante plataforma de IA sigue el ritmo acelerado de la investigación y el desarrollo de la IA en toda la industria tecnológica. En tan solo unos años, la cantidad de modelos alojados en el sitio ha crecido dramáticamente junto con el interés en el campo. En X, ingeniero de producto de Hugging Face, Caleb Fahlgren publicó un gráfico de modelos creados cada mes en la plataforma (y un enlace a otros gráficos), diciendo: “Los modelos van exponencialmente mes tras mes y septiembre ni siquiera ha terminado todavía”.
El poder del ajuste
Como lo insinuó Delangue anteriormente, la gran cantidad de modelos en la plataforma se debe a la naturaleza colaborativa de la plataforma y la práctica de ajustar los modelos existentes para tareas específicas. Ajustar significa tomar un modelo existente y darle entrenamiento adicional para agregar nuevos conceptos a su red neuronal y alterar la forma en que produce resultados. Desarrolladores e investigadores de todo el mundo aportan sus resultados, dando lugar a un gran ecosistema.
Por ejemplo, la plataforma alberga muchas variaciones de los modelos Llama de peso abierto de Meta que representan diferentes versiones ajustadas de los modelos base originales, cada una optimizada para aplicaciones específicas.
El repositorio de Hugging Face incluye modelos para una amplia gama de tareas. Navegando por su página de modelos muestra categorías como conversión de imagen a texto, respuesta visual a preguntas y respuesta a preguntas en documentos en la sección “Multimodal”. En la categoría “Visión por computadora”, existen subcategorías para estimación de profundidad, detección de objetos y generación de imágenes, entre otras. También están representadas las tareas de procesamiento del lenguaje natural, como la clasificación de textos y la respuesta a preguntas, junto con modelos de audio, tabulares y de aprendizaje por refuerzo (RL).
abrazando la cara
Cuando se clasifica por “la mayoría de las descargas“, la lista de modelos de Hugging Face revela tendencias sobre qué modelos de IA las personas encuentran más útiles. En la cima, con una enorme ventaja con 163 millones de descargas, se encuentra Transformador de espectrograma de audio del MIT, que clasifica contenidos de audio como voz, música y sonidos ambientales. Le sigue con 54,2 millones de descargas. BERT de Google, un modelo de lenguaje de inteligencia artificial que aprende a comprender el inglés prediciendo palabras enmascaradas y relaciones entre oraciones, lo que le permite ayudar con diversas tareas lingüísticas.
Completando los cinco principales modelos de IA se encuentran todo-MiniLM-L6-v2 (que asigna oraciones y párrafos a representaciones vectoriales densas de 384 dimensiones, útil para la búsqueda semántica), Transformador de visión (que procesa imágenes como secuencias de parches para realizar la clasificación de imágenes) y OpenAI ACORTAR (que conecta imágenes y texto, permitiéndole clasificar o describir contenido visual usando lenguaje natural).
No importa cuál sea el modelo o la tarea, la plataforma sigue creciendo. “Hoy en día se crea un nuevo repositorio (modelo, conjunto de datos o espacio) cada 10 segundos en HF”, escribe Delangue. “En última instancia, habrá tantos modelos como repositorios de códigos y ¡estaremos aquí para ello!”







