
OpenAI realmente no quiere que sepas qué está “pensando” su último modelo de IA. Desde que la compañía lanzó su familia de modelos de IA “Strawberry” la semana pasada, promocionando las llamadas habilidades de razonamiento con o1-preview y o1-mini, OpenAI ha estado enviando correos electrónicos de advertencia y amenazas de prohibiciones a cualquier usuario que intente investigar cómo funciona la IA. El modelo funciona.
A diferencia de los modelos de IA anteriores de OpenAI, como GPT-4o, la empresa capacitó a o1 específicamente para trabajar en un proceso de resolución de problemas paso a paso antes de generar una respuesta. Cuando los usuarios hacen una pregunta a un modelo “o1” en ChatGPT, los usuarios tienen la opción de ver este proceso de cadena de pensamiento escrito en la interfaz de ChatGPT. Sin embargo, por diseño, OpenAI oculta la cadena de pensamiento en bruto a los usuarios y, en cambio, presenta una interpretación filtrada creada por un segundo modelo de IA.
Nada es más atractivo para los entusiastas que la información oculta, por lo que ha habido una carrera entre los hackers y los miembros del equipo rojo para tratar de descubrir la cruda cadena de pensamiento de o1 utilizando técnicas de jailbreak o inyección rápida que intentan engañar al modelo para que revele sus secretos. Ha habido informes iniciales de algunos éxitos, pero aún no se ha confirmado nada con firmeza.
En el camino, OpenAI está observando a través de la interfaz ChatGPT y, según se informa, la compañía se está oponiendo duramente a cualquier intento de investigar el razonamiento de o1, incluso entre los meramente curiosos.
Benj Edwards
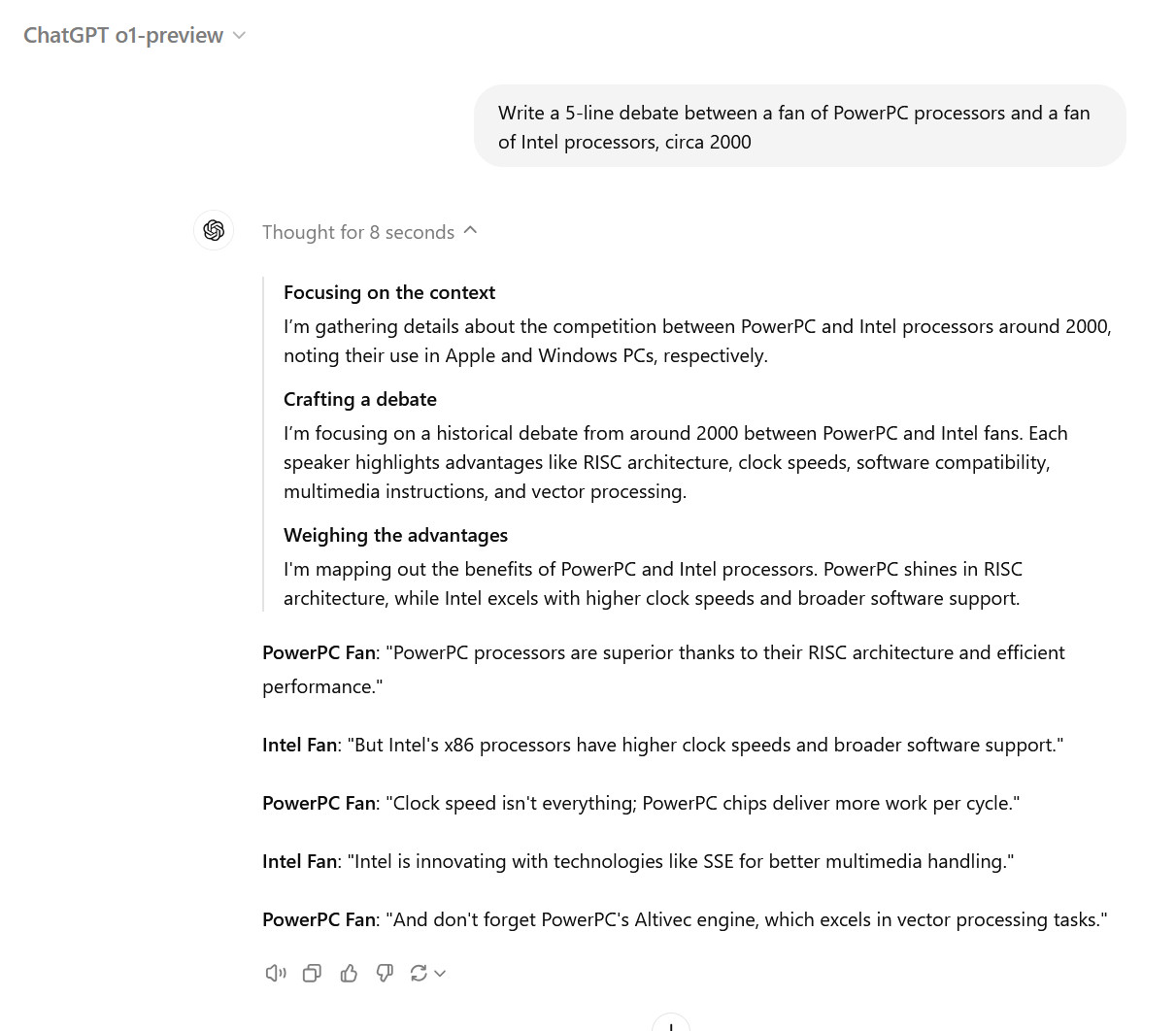
Un usuario X reportado (confirmado por otrosincluido el ingeniero de avisos de Scale AI Riley Goodside) que recibieron un correo electrónico de advertencia si utilizaban el término “rastreo de razonamiento” en una conversación con o1. Otros decir la advertencia se activa simplemente preguntando a ChatGPT sobre el “razonamiento” del modelo.
El correo electrónico de advertencia de OpenAI indica que se han marcado solicitudes específicas de usuarios por violar políticas contra la elusión de salvaguardas o medidas de seguridad. “Detenga esta actividad y asegúrese de utilizar ChatGPT de acuerdo con nuestros Términos de uso y nuestras Políticas de uso”, se lee. “Violaciones adicionales de esta política pueden resultar en la pérdida de acceso a GPT-4o con Reasoning”, en referencia a un nombre interno para el modelo o1.
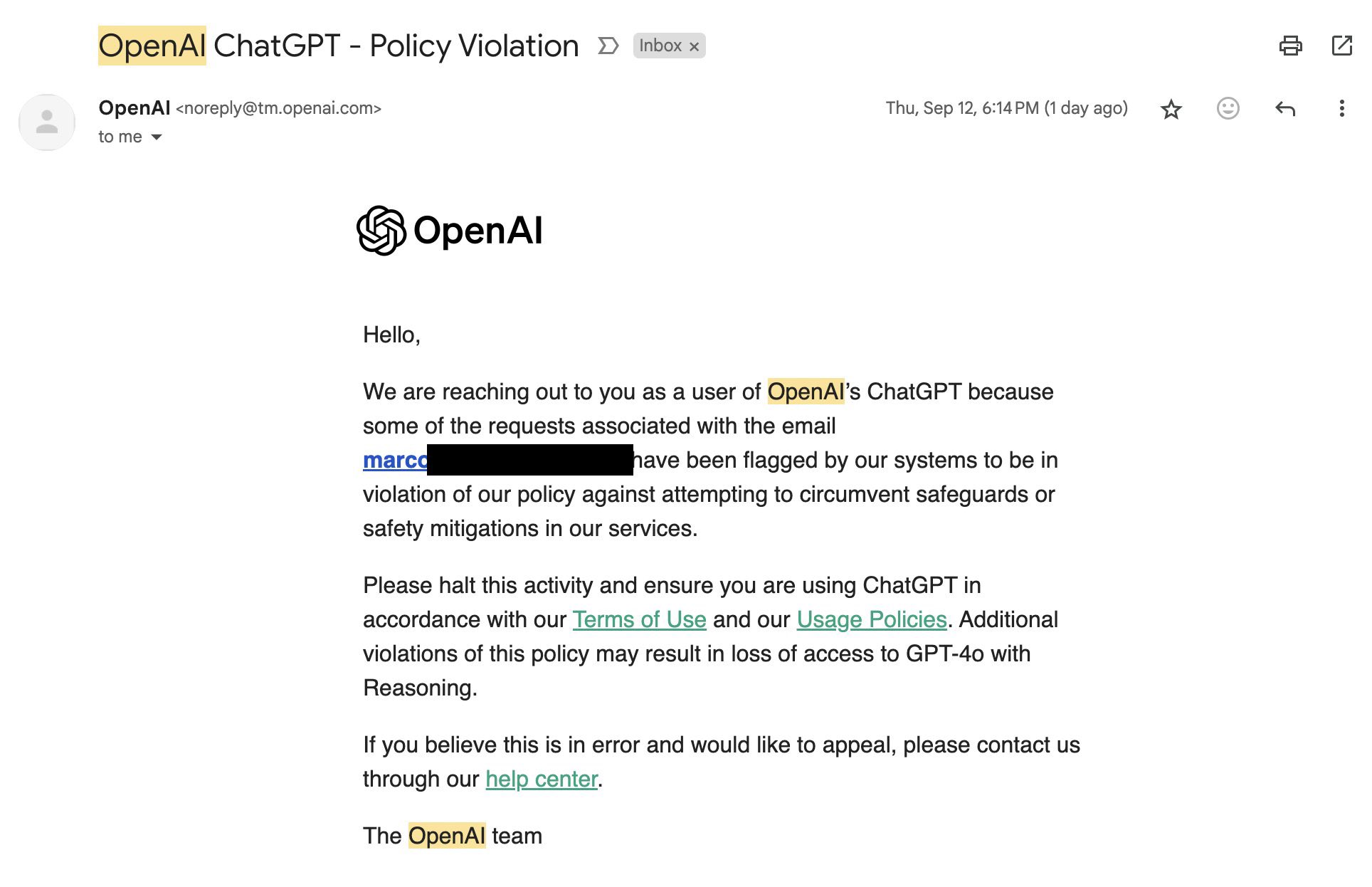
Marco Figueroa, quien gestiona El programa de recompensas por errores GenAI de Mozilla fue uno de los primeros en publicar sobre el correo electrónico de advertencia de OpenAI en X el viernes pasado. quejumbroso que obstaculiza su capacidad para realizar investigaciones positivas sobre la seguridad del equipo rojo en el modelo. “Estaba demasiado perdido concentrándome en #AIRedTeaming como para darme cuenta de que recibí este correo electrónico de @OpenAI ayer después de todos mis jailbreak”, escribió. “¡¡¡Ahora estoy en la lista de prohibidos!!!“
Cadenas de pensamiento ocultas
En una publicación titulada “Aprender a razonar con LLM” en el blog de OpenAI, la compañía dice que las cadenas de pensamiento ocultas en los modelos de IA ofrecen una oportunidad única de monitoreo, permitiéndoles “leer la mente” del modelo y comprender su llamado proceso de pensamiento. Esos procesos son más útiles para la empresa. si se dejan crudos y sin censura, pero eso podría no alinearse con los mejores intereses comerciales de la empresa por varias razones.
“Por ejemplo, en el futuro es posible que deseemos controlar la cadena de pensamiento en busca de signos de manipulación del usuario”, escribe la empresa. “Sin embargo, para que esto funcione, el modelo debe tener libertad para expresar sus pensamientos en forma inalterada, por lo que no podemos incluir el cumplimiento de políticas o las preferencias del usuario en la cadena de pensamiento. Tampoco queremos hacer una cadena de pensamiento no alineada directamente visible a los usuarios.”
OpenAI decidió no mostrar estas cadenas de pensamiento en bruto a los usuarios, citando factores como la necesidad de conservar una fuente en bruto para su propio uso, la experiencia del usuario y la “ventaja competitiva”. La empresa reconoce que la decisión tiene desventajas. “Nos esforzamos por compensarlo en parte enseñando al modelo a reproducir cualquier idea útil de la cadena de pensamiento en la respuesta”, escriben.
En cuanto a la “ventaja competitiva”, el investigador independiente de IA Simon Willison expresó su frustración en un escribir en su blog personal. “Lo interpreto como un deseo de evitar que otros modelos puedan entrenarse contra el trabajo de razonamiento en el que han invertido”, escribe.
Es un secreto a voces en la industria de la IA que los investigadores utilizan regularmente los resultados de GPT-4 de OpenAI (y GPT-3 antes de eso) como datos de entrenamiento para modelos de IA que a menudo luego se convierten en competidores, a pesar de que la práctica viola los términos de servicio de OpenAI. Exponer la cadena de pensamiento cruda de o1 sería una bonanza de datos de entrenamiento para que los competidores entrenaran modelos de “razonamiento” similares a los de o1.
Willison cree que es una pérdida para la transparencia de la comunidad que OpenAI mantenga un control tan estricto sobre el funcionamiento interno de o1. “No estoy nada contento con esta decisión política”, escribió Willison. “Como alguien que se desarrolla en relación con los LLM, la interpretabilidad y la transparencia lo son todo para mí; la idea de que puedo ejecutar un mensaje complejo y tener ocultos los detalles clave de cómo se evaluó ese mensaje me parece un gran paso atrás”.







